
ChatGLM3部署与微调
前言
写这篇文章主要是记录在部署ChatGLM3时遇到的一些坑,避免朋友们以后遇到类似问题
文章默认你拥有:python
部署方法
克隆文件
1.直接下载main文件到本地
2.使用git克隆
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
下载模型
首先我们进入ChatGLM3-6B官网下载与你电脑相匹配的模型(如果不下载到本地,运行时会自动联网加载模型,但这往往很慢)
正常情况下下载ChatGLM3-6B就足够了,关于‘量化(低成本部署)’我们可以更改代码来实现
需要注意的是,下载的文件格式可能默认为txt文件,需要对照下载链接的文件一个一个更改
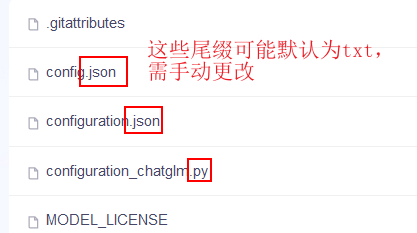
修改模型路径
将下载后的文件统一放在一个文件夹中,并记住路径(推荐与main文件放在一起)
接着打开任意demo,这里打开 ChatGLM3-main\basic_demo\cli_demo.py ,这是一个在控制台进行对话的demo
进入demo后,进行路径配置:
model_path = "E:\\ChatGLM3\\ChatGLM3-main\\model"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).quantize(4).cuda()
1.文件路径这里使用的是绝对路径,你也可以修改为相对路径
2.在model变量那一行,添加.quantize(4),进行int4量化,或改为.quantize(8),进行int8量化
3.int4量化最低显存为4GB,int8量化最低显存为6GB(正常6GB显卡无法运行,你的其他应用会默认占用一些显存),若不进行量化,则最低显存为13GB
4.如果你的显卡实在运行不了,可以使用CPU部署(需要28GB内存),只需将代码 .quantize(4).cuda() 改为 .float() 即可
配置环境
安装若干包
1.在主路径上输入cmd进入面板
2.网络环境允许的情况下,使用 pip install -r requirements.txt直接安装
如果网络较差:
使用镜像安装,对照requirements.txt中的每个包,在后面加上镜像的路径
eg.pip install transformers==4.30.2 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
1.transformers 库版本应该 4.30.2 以及以上的版本 ,torch 库版本应为 2.0 及以上的版本,以获得最佳的推理性能
2.gradio 库版本应该为 3.x 的版本
3.为了保证 torch 的版本正确,请先不要安装,继续参考后续教程
安装cuda环境
由于cuda仅限NVIDIA的显卡才可使用,如果你不是该类显卡,请参考其他教程
在安装了显卡驱动的前提下,cmd中输入:nvidia-smi查看支持的最高cuda版本
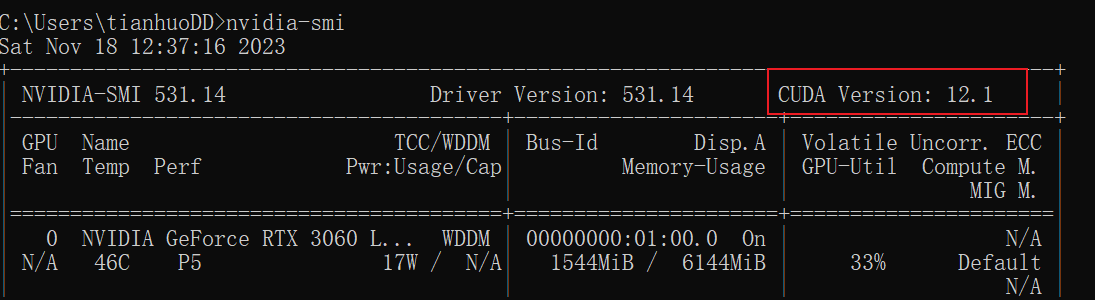
确认版本后,前往CUDA官网找到适合你电脑的版本,点击下载安装即可
安装torch
如果你安装了torch包请查看它的版本,确保它>=2.0 并且适配cuda和python版本,查看适配版本
如果你没有安装,请在cmd输入python,查看你的python版本

请记住你的python和cuda版本
例如,我的python版本为3.11,cuda版本为12.1,电脑为win 64位,则下载
![]/(upload/chatglm/chatglm5.png)
一定要下载torch>=2.0的版本哦
下载完成后,在chatglm3主路径上输入cmd进入面板,输入 pip install torch-2.1.0+cu121-cp311-cp311-win_amd64.whl进行安装,这里的whl文件根据你实际下载的进行更改
检验:在cmd中输入以下代码,如果显示为True,则证明成功安装适配版本
python
import torch
torch.cuda.is_available()
部署完成
看到这里说明你已经成功部署了!这是本人第一次写的技术博文,如有不明白的地方可以在评论区直接提出,我会抽时间回答的,如文章中有错误也欢迎指正!
常见报错解决方案:秋风于渭水
微调方法
目前还没有研究,可以参考LLaMA-Factory项目
{kind=link}
{kind=link}