
Neo4j学习
2023-12-09
Neo4j安装
中文社区版安装及使用
安装中文社区版,需要注意的是要安装对应版本的JDK,否则会报错
安装完成后,右键编辑 bin目录下的 neo4j.bat,添加对应jdk的位置:SET "JAVA_HOME=E:\JDK17\jdk17" (只需要写到jdk目录即可,无需到bin目录)

设置完成后,从 bin目录下打开cmd面板,输入 neo4j console启动社区版服务
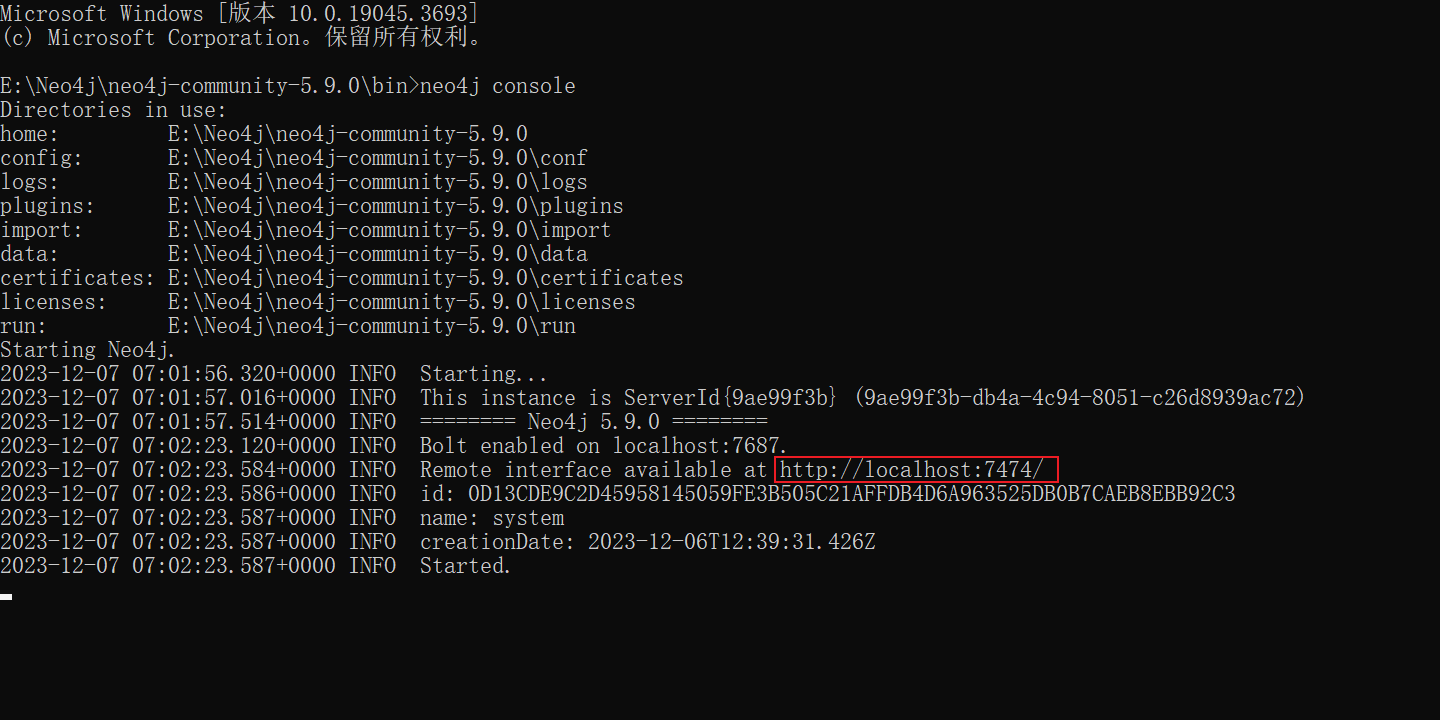
接着在浏览器中输入:http://localhost:7474/(英文版)即可进入数据库控制台,也可以输入:http://doc.we-yun.com:10010(中文版)
初次进入控制台,默认连接url为:localhost:7687 默认用户名:neo4j 默认密码:neo4j
进入后会让你修改一次密码,记住即可
社区版服务启动
需要注意的是,从 bin目录下使用 neo4j console启动服务,是暂时的,关闭cmd面板后就会自动关闭服务
如果你需要长期打开服务,请使用下述操作:
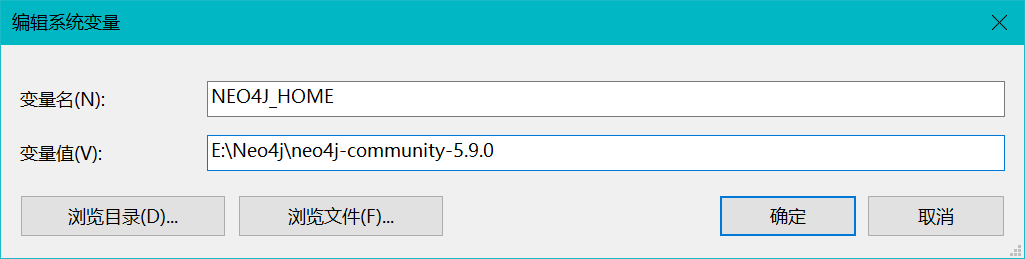
进入环境变量设置:
添加:NEO4J_HOME:E:\Neo4j\neo4j-community-5.9.0
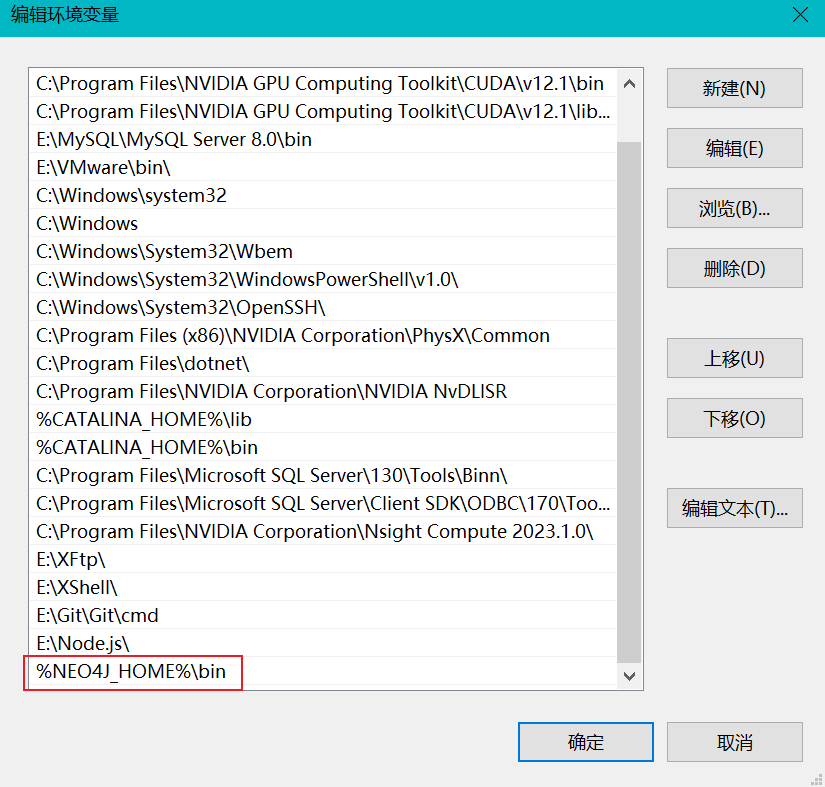
进入Path变量设置:
新建:%NEO4J_HOME%\bin
这时打开cmd面板(以管理员启动),输入 neo4j -verbose验证是否配置成功
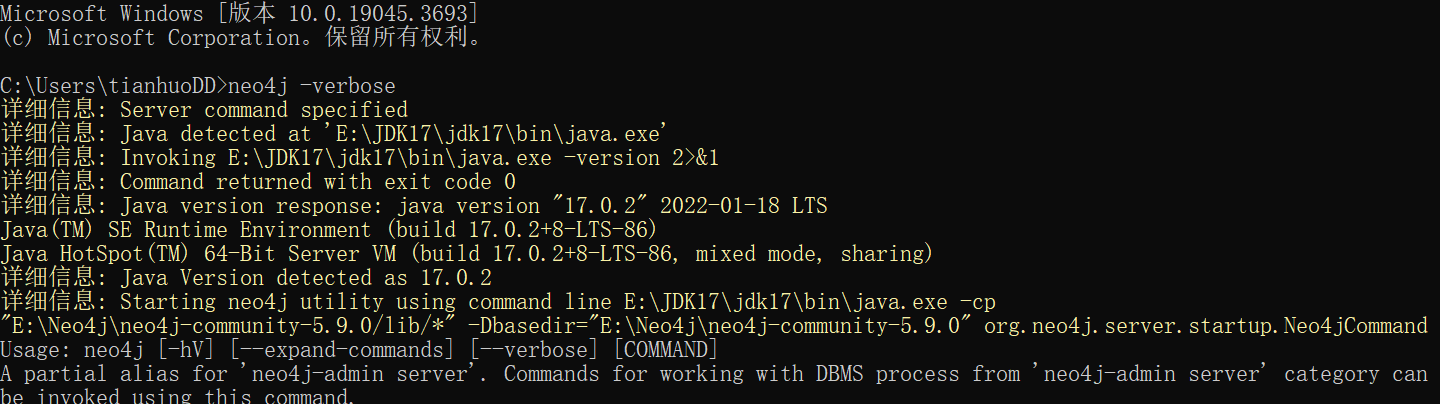
如果显示上述信息,则成功;否则请自寻查找错误原因(建议cmd重新打开后再输入)
接着我们输入 neo4j install-service安装neo4j服务,但你往往会遇到以下错误:

解决方法:在 neo4j的 bin目录下运行cmd,输入:neo4j.bat windows-service install,安装成功
接着我们可以在任意cmd中输入 neo4j start启动neo4j服务;停止服务使用 neo4j stop
如果出现以下错误,则说明你neo4j服务已启动,无需重复:

cypher-shell的使用
正常情况下,在cmd中使用 cypher-shell -d neo4j或 cypher-shell -d system即可进入neo4j或system数据库;接着输入用户名和密码就可以进行操作[注意:你需要先启动neo4j服务:neo4j start
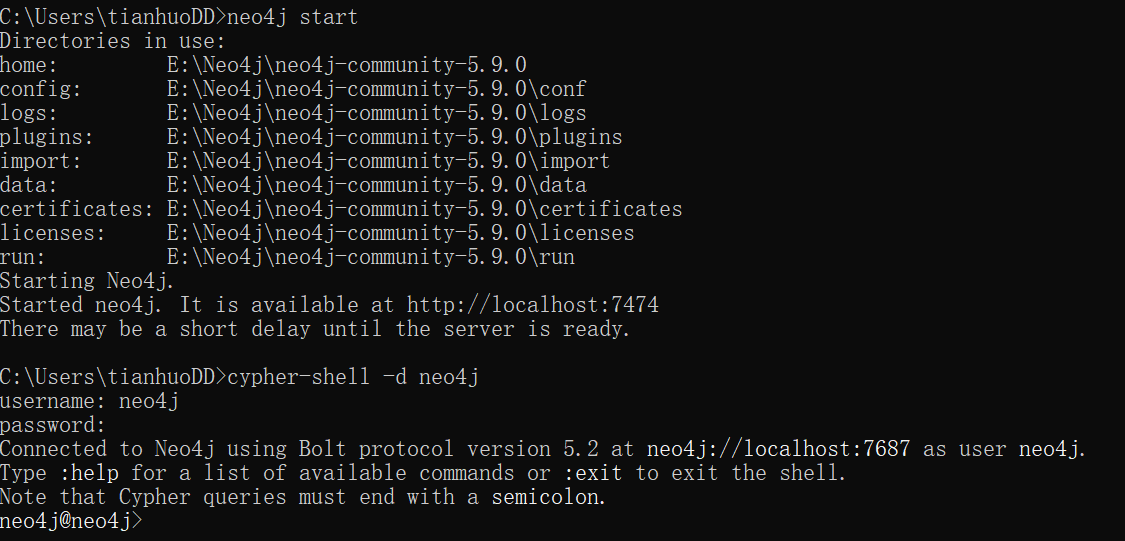
如果你的默认java版本和你的neo4j所需版本不对应需使用以下方法:
首先在 bin中找到 cypher-sehll文件,右键编辑,找到 if "%JAVACMD%"=="" set JAVACMD=java,将其改为:set JAVACMD="E:\JDK17\jdk17\bin\java.exe"即可正常启动

Cypher语言基础
本节内容参考:大龄码农生活
Cypher即CQL语言,是Neo4j的查询语言
常用CQL命令:
| S.No. | CQL命令/条 | 用法 |
|---|---|---|
| 1. | CREATE 创建 | 创建节点,关系和属性 |
| 2. | MATCH 匹配 | 检索有关节点,关系和属性数据 |
| 3. | RETURN 返回 | 返回查询结果 |
| 4. | WHERE 哪里 | 提供条件过滤检索数据 |
| 5. | DELETE 删除 | 删除节点和关系 |
| 6. | REMOVE 移除 | 删除节点和关系的属性 |
| 7. | ORDER BY以…排序 | 排序检索数据 |
| 8. | SET 组 | 添加或更新标签 |
CREAT 创建
一、创建节点
1.1 创建没有属性的节点
CREATE (<node-name>:<label-name>)
<node-name>:表示新创建节点的标识符,只在当前查询有效
<label-name>:表示节点的标签名,会在节点中显示
eg.CREATE (tmp:大学) return tmp 或 CREATE (:大学)
前者使用时需带return命令(因为 tmp仅在当前语句有效);后者为常用创建节点命令
一般情况下,
:前的内容为临时标识符,用于简化后续操作
1.2 创建具有属性的节点
CREATE (:<label-name> {<key>:<value>,...,<n-key>:<n-value>})
它的属性以键值对的形式保存
eg.CREATE (:大学{name:"清华大学",score:700})
1.3 创建多标签节点
CREATE (<node-name>:<label-name1>:<label-name2>)
使用此语句可以创建一个节点,具有多个标签
eg.CREATE (:大学1:大学2)
1.4返回创建的节点
CREATE (<node-name> { name: "" }) RETURN <node-name>
使用此方法创建,没有标签,一般用于临时数据检索
eg.CREATE (a {name:"Andres"}) RETURN a
二、创建关系
2.1 建立关系
CREATE (node1)-[:RelationshipType]->(node2)
创建关系需要使用 ->指示关系
eg.直接创建节点及关系
CREATE (tmp1:大学{name:"清华大学",score:700})
CREATE (tmp2:学院{name:"计算机学院",count:3000})
CREATE (tmp1)-[r:包含]->(tmp2)
RETURN tmp1,tmp2
eg.匹配现有节点创建关系
MATCH (a:大学),(b:学院)
WHERE a.name="清华大学" AND b.name="计算机学院"
CREATE (b)-[r:被包含]->(a)
RETURN a,b
[r:被包含]中
r为标识符,可以使用RETURN r直接返回a、b间的关系
2.2 创建关系的属性
CREATE (node1)-[:RelationshipType{key:value,...,n-key:n-value}]->(node2)
在关系命名中,直接使用 {}来创建关系的属性,用于说明连接本身的含义
一般可以使用权重、状态、时间等属性
eg.
MATCH (a:大学),(b:学院)
WHERE a.name="清华大学" AND b.name="计算机学院"
CREATE (b)-[r:提高知名度{time:"2023-12-7"}]->(a)
RETURN a,b
2.3 创建完整路径
CREATE p = (<node-name>:<label-name> {key:value})-[:RelationshipType]->(<node-name>:<label-name> {key:value})[:RelationshipType]->(<node-name>:<label-name> {key:value})
RETURN p
创建完整路径的同时会创建新的节点(会先检索节点是否存在)
创建完整路径语义更清晰,整体性更好;单独创建可以针对单个节点关系细节操作。
eg.
CREATE p = (:大学 {name:"清华大学"})-[:包含]->(:学院 {name:"计算机学院"})<-[:属于]-(:专业 {name:"软件工程"})
RETURN p
2.4 创建索引
CREATE INDEX ON :<label-name>(key)
创建索引后基于 <key>属性的查询会执行更快
eg.CREATE INDEX ON :大学(name)
需要注意的是,上述语句用于在Neo4j 的旧版本使用,在新版本中使用:
CREATE INDEX FOR (n:大学) ON (n.name)
MATCH 匹配
一、查询节点
1.1 查询所有节点
MATCH (n)
RETURN n
1.2 查询指定标签的属性
MATCH (<node-name>:<label-name>)
RETURN <node-name>.<key>
<key>指属性
eg.MATCH (a:大学) RETURN a.name
1.3 查询关联节点
MATCH (:<label-name1>{key:value})--(<node-name>:<label-name2>)
RETURN <node-name>.<key>
查询所有 <label-name1>{key:value}与之关联的,<label-name2>的 <key>属性
eg.
MATCH (:大学{name:"清华大学"})--(a:学院)
RETURN a.name
二、查询关系
2.1 查询节点间指向关系
MATCH (:<label-name>{key:value})-->(<node-name>)
RETURN <node-name>.<key2>
查询所有 属性为key:value的<label-name>指向的所有节点,返回其 <key2>属性
这里的 <node-name>用于临时查询
eg.
MATCH (:大学{name:"清华大学"})-->(tmp)
RETURN tmp.name
匹配 name为 清华大学的 大学标签 指向 的所有节点,返回其 name值
2.2 查询节点间的关系
MATCH (:<label-name>{key:value})-[r]->(<node-name>)
RETURN type(r)
当需要过滤关系中的属性,或者返回关系的时候,变量就很有必要了
eg.
MATCH (:大学{name:"清华大学"})-[r]->(tmp)
RETURN type(r)
查询 清华大学指向其他节点的关系有哪些
2.3 匹配关系类型
MATCH (:<label-name>{key:value})-[:RelationshipType]->(<node-name>)
RETURN <node-name>.name
查询指定关系的节点属性
eg.
MATCH (:大学{name:"清华大学"})-[:包含]->(tmp)
RETURN tmp.name
2.4 匹配多种关系类型
MATCH (:<label-name>{key:value})-[:RelationshipType|:RelationshipType2]->(<node-name>)
RETURN <node-name>.name
当需要匹配多种关系类型时,可以使用 |隔开,表示或者
2.5 查找关系的属性
MATCH (:大学{name:"清华大学"})-[r:包含]->(tmp2)
RETURN r.name
2.6 多个关系
MATCH (tmp{name:"清华大学"})-[:包含]->(tmp2)<-[:属于]-(tmp3)
RETURN tmp,tmp2,tmp3
2.7 可变长关系
-[:RelationshipType*minHops..maxHops]->
minHops和maxHops都是可选的,默认值分别为1和无穷大
eg.
CREATE p=(:大学{name:"清华大学"})-[:是]->(:形容词{name:"最好"})-[:是]->(:称谓{name:"大学"})
WITH p
MATCH (tmp{name:"清华大学"})-[tmp2:是*1..3]->(tmp3)
RETURN tmp2
返回 1跳到 3跳的所有关系
三、查询路径
3.1 单条最短路径
MATCH p =shortestPath((tmp{name:"清华大学"})-[*..15]-(tmp2{name:"软件工程"}))
RETURN p
[*..15]表示查找长度不超过 15 的路径
这里并没有使用 ->指定关系,则表示所有路径都会被查询;这里也未使用 :大学进行标签限制,实际时用时按需更改
3.3 通过id查询节点或关系
MATCH(n)
WHERE id(n) IN [0,3,5]
RETURN n
上述为使用id查询节点,可以查询多个节点
也可使用 WHERE id(n)=0查询单个节点
MATCH ()-[r]->()
WHERE id(r)= 0
RETURN r
上述为使用id查询关系,但不推荐使用此方法(因为id可能会在数据库操作中变化),后续可能被 Neo4j弃用
四、可选匹配
MATCH (a:大学{name:"清华大学"})
OPTIONAL MATCH (a)-->(x)
RETURN x
OPTIONAL MATCH为可选匹配,当存在此条件时会显示节点,否则返回null
也可以指定关系类型:OPTIONAL MATCH (a)-[:RelationshipType]->(x)
WHERE 过滤
WHERE子句一般用来过滤MATCH查询的结果。
布尔运算符:AND、OR、NOT、XOR {异或}
比较运算符:=、<>{不等于}、<、>、<=、>=
一、基本使用
MATCH (tmp:大学)
WHERE tmp.name = "清华大学" AND tmp.score > 300
RETURN tmp
上述是运算符的基本使用
MATCH (n)
WHERE exists(n.score)
RETURN n
上述的 exists()函数用于检查节点或关系的某个属性是否存在
不过在 Neo4j新版中已经弃用,现在应使用:WHERE n.score IS NOT NULL
二、字符串匹配
2.1 匹配字符串的开始
MATCH (n)
WHERE n.name STARTS WITH '清华'
RETURN n
STARTS WITH用于以大小写敏感的方式匹配字符串的开始部分
2.2 匹配字符串的结尾
MATCH (n)
WHERE n.name ENDS WITH '大学'
RETURN n
ENDS WITH用于以大小写敏感的方式匹配字符串的结尾部分
2.3 字符串包含
MATCH (n)
WHERE n.name CONTAINS '华大'
RETURN n
CONTAINS用于以大小写敏感的方式匹配字符串,不必关系它的位置
2.4 字符串反向匹配
MATCH (n)
WHERE NOT n.name CONTAINS '华大'
RETURN n
使用 NOT进行反向匹配
2.5 正则表达式匹配
MATCH (n)
WHERE n.name =~ '(?i).*清华.*'
RETURN n
使用 =~''来进行正则匹配
三、模式过滤/匹配路径
MATCH (n { name:'软件工程'}),(m)
WHERE (n)-[:属于]-(m)
RETURN n,m
返回 name为 软件工程、且关系为 属于路径
MATCH (n { name:'软件工程'}),(m)
WHERE NOT (n)-[:属于]-(m)
RETURN n,m
使用 NOT过滤
MATCH (n)-[r]->(m)
WHERE type(r)=~ 'DIRE.*'
RETURN n , m
四、IN运算符
MATCH (a)
WHERE a.name IN ['清华大学', '软件工程']
RETURN a
检查列表中是否存在某个元素,可以使用IN运算符。
RETURN 返回
上述其他操作中已经讲诉大多 RETURN方式,这里只说明其他方法
MATCH (a:大学{name:"清华大学"})
RETURN *
当你不想思索到底要返回什么时,可以直接使用 *返回全部相关节点
MATCH (a:大学{name:"清华大学"})
RETURN a.score AS 高考分数线
上述操作使用 AS用作重命名 a.score的字段名,仅在当前查询有效,使数据便于理解
MATCH (a)
RETURN DISTINCT a.name
DISTINCT用于去除查询中的重复值,一般用于统计唯一值时
其他常用命令
一、MERGE
MERGE命令是CREATE命令和MATCH命令的组合;
使用MERGE进行操作,会检查创建的节点或关系是否存在,若存在则匹配,否则创建
MERGE (a:大学)
RETURN a, labels(a)
这里的 labels(a)是返回标签名
二、CREATE UNIQUE
需要注意的是这并不是创建唯一约束,而是用于确保路径的唯一性;当存在要创建的路径时,则重用这些部分,不存在则创建
CREATE UNIQUE (a:大学)-[r:包含]->(b:学院)
RETURN *
MERGE和``CREATE UNIQUE`的区别:
| 区别 | MERGE | CREATE UNIQUE |
|---|---|---|
| 用途 | Neo4j中常用 | 在Neo4j新版本中已弃用 |
| 行为 | 完全匹配节点或路径,若找到则使用,否则创建全部部分 | 匹配路径是否存在,若部分缺失仅补全缺失部分 |
| 限制 | 节点和路径都适用 | 仅适用于创建路径 |
三、SET命令
用于在现有节点或关系添加或更改属性
1、更改属性
MATCH (n{score:700})
SET n.name="北京大学"
RETURN n
使用 MATCH匹配你要更改的节点,SET来更改该节点的属性
2、删除属性
MATCH (n{name:"清华大学"})
SET n.name=NULL
RETURN n
一般使用 REMOVE来删除属性,也可以随时使用 SET来删除
3、添加属性
MATCH (n:大学)
SET n+={name:"南京大学",score:680}
RETURN n
使用 SET +=和 直接使用 SET有细微的区别,但影响不大
4、添加标签
MATCH (n{name:"南京大学"})
SET n:南京
RETURN n
上述操作可以添加一个标签,也可以使用 SET n:南京:985可以添加多个标签
四、DELETE 删除
Neo4j使用
DELETE子句,必须和MATCH结合使用
// 删除所有指向关系
MATCH ()-[r]-() DELETE r
// 删除所有标签为`大学`的节点
MATCH (n:大学) DELETE n
需要注意的是,如果节点存在外部关系,则不能直接删除,需先断开所有关系
如果你想要强制删除某个节点,可以使用 DETACH DELETE,它会先删除与之联系的关系,再删除节点:
MATCH (n:大学)
DETACH DELETE n
如果你想要删除全部数据,可以使用下述命令,但其仅适用于删除少量数据:
MATCH (n)
DETACH DELETE n
注意:删除操作无法撤销,请谨慎使用!
五、REMOVE 删除
Neo4j CQL DELETE和REMOVE命令之间的主要区别 :
- DELETE操作用于删除节点和关联关系
- REMOVE操作用于删除标签和属性
MATCH (n{name:"南京大学"})
// 删除节点的属性
REMOVE n.name
// 删除节点的标签
REMOVE n:大学
RETURN n
六、ORDER BY 相关
1、ORDER BY 排序
默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用DESC子句
MATCH (n)
RETURN n.name
// 升序排列
ORDER BY n.name
// 降序排列
ORDER BY n.name DESC
2、LIMIT 限制输出
MATCH (n)
RETURN n
ORDER BY n.name
// 限制输出三行
LIMIT 3
3、SKIP (偏移量)
MATCH (n)
RETURN n
ORDER BY n.name
// 跳过前三个,从第三行开始返回结果
SKIP 3
4、实现分页
MATCH (n)
RETURN n
ORDER BY n.name
// 从第11行开始,返回5行
SKIP 10
LIMIT 5
七、WITH 和
将结果传递到后续查询之前对结果进行操作,用于将上个语句传输到下个语句中
注意:WITH 会影响查询结果集里的变量,WITH 语句外的变量不会传递到后续查询中
1、对结果进行筛选
MATCH (David{name: 'David'})--(otherPerson)--()
// 在判断值前进行聚合,得到数量
WITH otherPerson, count(*) as cnt
WHERE cnt > 1
RETURN otherPerson.name
MATCH (David{name: 'David'})--(otherPerson)--()表示从David开始,无向关系到其他节点,再从其他节点无向到其他节点;即匹配所有与David有关的节点
2、对结果进行排序
MATCH(n)
// 排序后将结果返回给后方查询
WITH n
ORDER BY n.name desc
WHERE nperson.name = 'David' or nperson.name = 'Bossman'
RETURN collect(nperson.name)
3、限制搜索路径分支
MATCH (n { name: 'Tom Hanks' })--(m)
// 限制匹配路径的数量
WITH m
ORDER BY m.name DESC LIMIT 1
MATCH (m)--(o)
RETURN o.name
总的来说,
WITH起一个承上启下的作用;在Neo4j新版本中,使用CREAT创建节点若需要直接引用,需要使用WITH进行承接
八、FOREACH 循环
FOREACH语句用于循环遍历结果集列表,然后做一些操作
MATCH (a {name: 'root' })
FOREACH (name IN ["Mike", "Carl", "Bruce"] | CREATE (a)-[:FRIEND]->(:Person {name: name}))
使用 FOREACH子句,在前半段为循环内容,后半段为进行的操作,使用 |分割
九、Aggregation 聚合
即常用的函数
// 计算节点数量
RETURN count(*)
// 返回类型
RETURN type(r)
// 计算和
RETURN sum(n.count)
// 计算平均值
RETURN avg(n.count)
// 最大值和最小值
RETURN max(n.count),min(n.count)
// 将所有值收集起来,放到列表中
RETURN collect(n.name)
// 计算不重复值的数量
RETURN count(DISTINCT n.count)
十、UNION 组合
用于将多个查询结果组合起来
MATCH (n:Actor)
RETURN n.name AS name
// 组合两个查询,包含重复行
UNION ALL
// 组合两个查询,移除重复值
// UNION
MATCH (n:Movie)
RETURN n.title AS name
十一、UNWIND (行转列)
// 将常量列表转为名为x的行并返回
UNWIND [1, 2, 3] AS x
RETURN x
// 将一个重复值列表,转为一个集合;即创建了唯一列表
WITH [1, 1, 2, 2] AS coll
UNWIND coll AS x
WITH DISTINCT x
RETURN collect(x) AS SET
十二、CALL (调用存储过程)
// 列出数据库所有标签
CALL `db`.`labels`
{kind=link}
{kind=link}